并发系列 -- 实践 -- 直播推流之帧率控制(1080p59.94, 1080p50)
一、项目背景
博主在职期间,负责赛事直播项目的 Windows 桌面端开发工作:
(1) AR 后台系统
AR后端充分利用 Qt Designer 提供的能力 (Custom Widget), 设计出一套能够快速集成各个算法模块的 标准化组件 。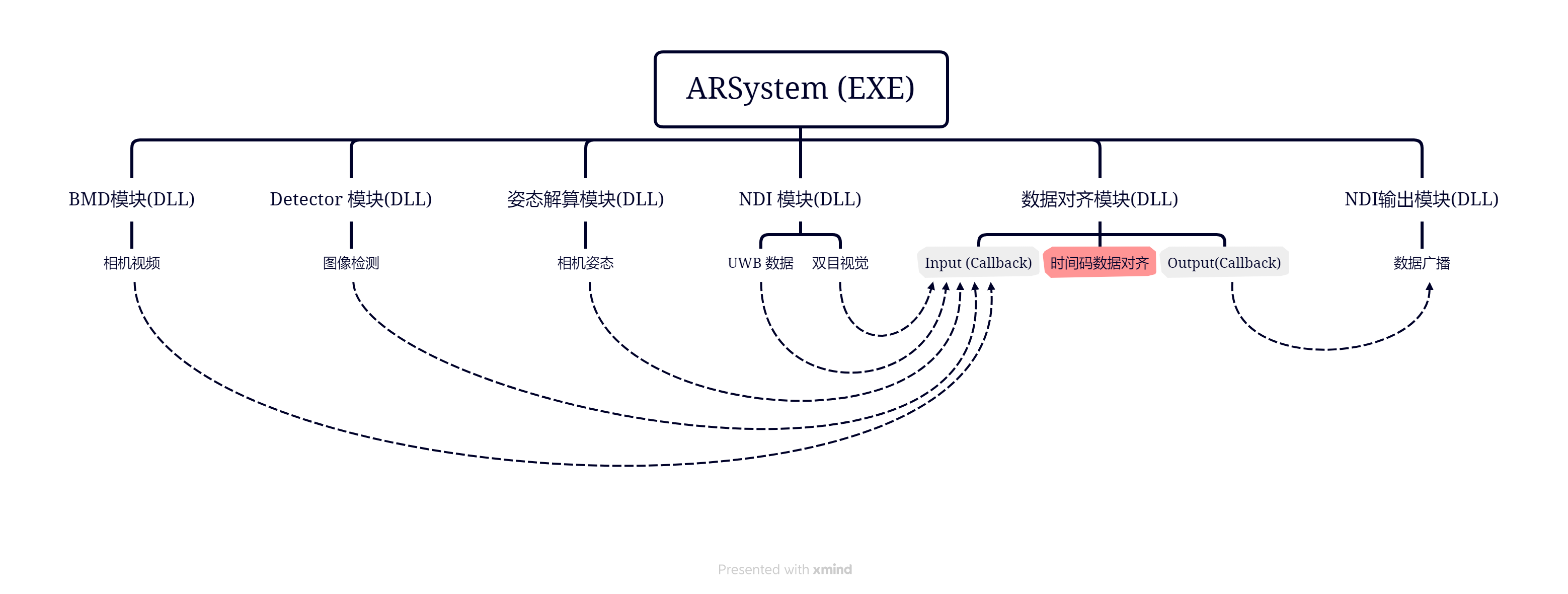
上图是由 QT 构建的实时处理系统,可划分为两大组成部分:
- 主框架(EXE):为各算法模块的运作提供了一致的行为规范,包括:加载、运行、状态监测、异常捕获(不完善)
- 算法模块(DLL):功能完备 的DLL,包括:界面 UI、算法处理、状态上报
相信 99% 的 QT 码农看到功能完备时,会一脸懵。 碍于本文主题,组件的标准化流程会在 Qt 系列文章中介绍。本文仅对 对齐模块 中涉及到的一些并发考虑作简要介绍。
(2) AR 前端渲染
AR Render 是使用 Unity 游戏引擎开发的赛事直播专用软件,3D 增强现实效果直达观众(用户)。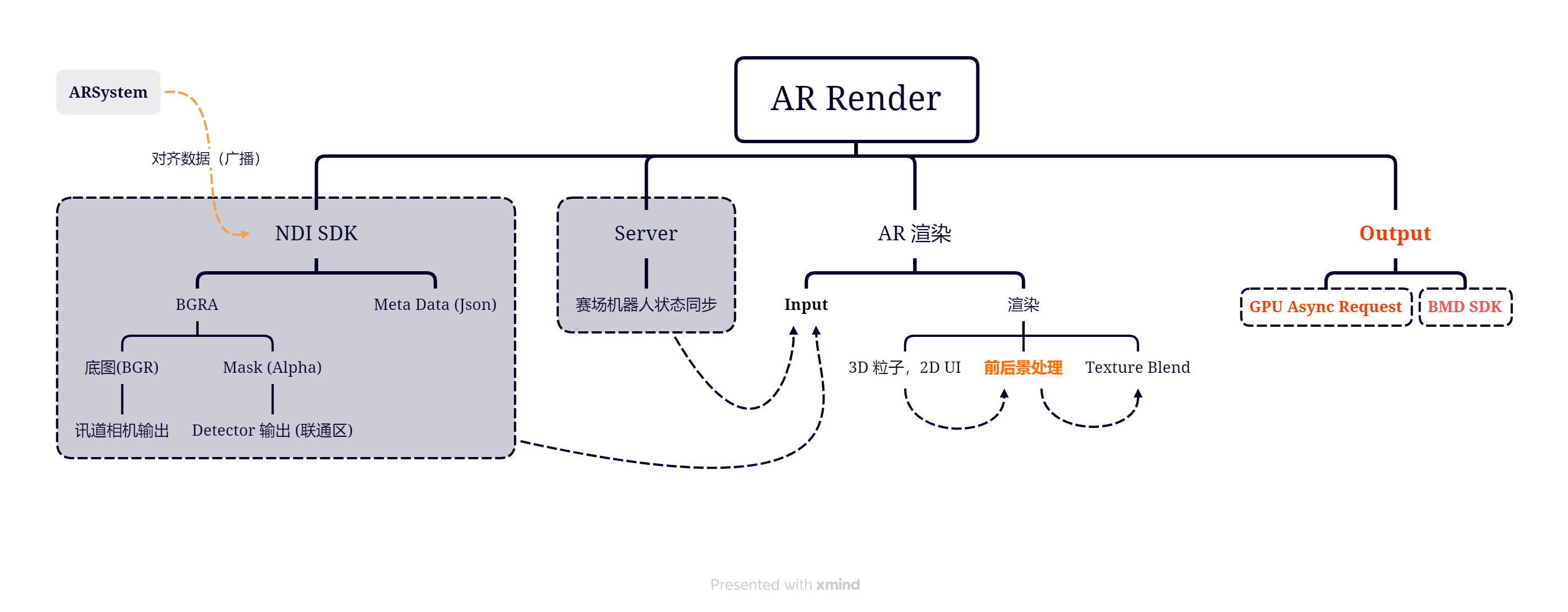
上图是赛事直播软件的基本构成。
图中橙色高亮部分不在本文讨论范围,可参考AR前后景概述。
图中红色高亮部分涉及强相关的两部分内容,包括:GPU 异步纹理请求,BMD SDK 纹理接收。BMD SDK 部分不在本文的讨论范围,因此,本文仅对 GPU 异步纹理请求的一些考虑作简要介绍。
二、并发细节考虑
并发实践的考虑,要么是为了达到性能指标、要么是为了将关注点分离。本文挑选上述 AR 直播系统中比较有挑战性的两个环节,展开对并发性能的一些论述。
(1) 数据对齐之帧率控制
1080p59.94 制式直播推流的帧间隔是 16.6ms。在整个数据处理链路中,某个环节需要进行数据收发,数据对齐,数据拼接等操作。
- 数据接收:会进行 ms 级别的 copy 操作
- 数据对齐环节: 会存在 ms 级的等待操作; 会存在 ms 级的数据copy (1080p BGR 大约占 3ms,跟CPU 频率强相关)
- 数据拼接环节:会存在 ms 级别的 格式转换(uyvy to bgra)
- 数据发送:会存在 ms 级别的阻塞(sdk 内部 copy 耗时)
上述的 wait, copy, format 操作远远超过了有限的 16.6ms 的帧间隔。为了保证稳定的 16.6ms 稳定输出,可以将数据处理划分为两个阶段:
- 阶段1:负责数据接收,数据对齐相关工作
- 阶段2:在发送环节,再进行相应的数据拼接操作
对整个实时系统来说,时延是最不可接受的。为了稳帧率,将单个阶段划分为两个阶段:不仅增加了线程间同步的负担,还需要一定的 buffer 作为缓冲,以减少帧率波动。调整后的数据处理流程,如下图所示: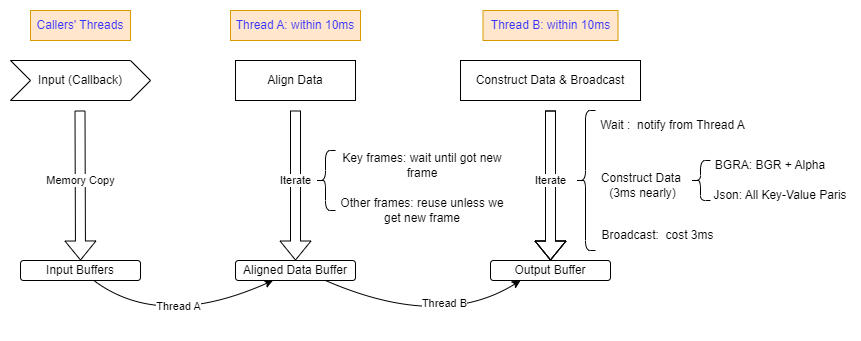
(2) GPU 图像获取之帧率控制
直播项目的应用场景涉及到的软硬件条件:Unity 渲染引擎、C++ SDK、BMD 采集卡。但本小节的前半部分不拘泥于特定的渲染引擎 (Unity, UE),特定的推流方案。我们只讨论并发相关的技术细节:GPU Request,Memory location
- Method 1:同步操作 + 同步操作
- Step 1: [Update]同步操作获取 GPU 纹理
- Step 2: [Update]将纹理数据 copy 至 SDK 内所维护的 数据结构
- Method 2: 异步操作 + 同步操作
- Step 1: [Update]异步获取 GPU 纹理(AsyncGPUReadback::Request),数据结构 frameQueue 维护纹理句柄;
- Step 2: [Update]遍历 frameQueue, 将所有就绪状态的纹理数据 Copy 至 SDK 内部 数据结构
- Method 3: 异步操作 + 异步操作
- Step 1: [Update]异步获取 GPU 纹理,frameQueue 维护异步纹理
- Step 2: [Update]遍历 frameQueue, 将所有就绪状态的纹理 句柄 传至 SDK 内部 无锁数据结构
- Step 3: [WaitForEndOfFrame]同步 SDK 内纹理句柄的无效状态,以告知 SDK 丢弃 未及时处理 的纹理句柄